Dynomite Remediation

Why Manual Remediation is a bad idea?
First of all, manual operations are complicated at Cloud / Microservices era, since we have more software and this software is often way more distributed it means we have more machines to deal with. More machines mean more steps because sometimes the changes are not only on the machine but on the underlying infrastructure like Launch configurations or auto-scaling groups. Apply this changes to Database infrastructure requires very specific ordering. Ordering is easy to determine but proper execution is hard. As humans we are great but we always make mistakes, also like Google SRE folks said in the past, everytime you add a human you will introduce latency. Latency might be okay for 1 cluster, but for several clusters, it's a bigger problem. Wrapping up: Cloud Operation Manual work has these potential problems:
- Error-Prone: Mistakes or lack of attention to detail
- Latency: It's will take more time to get the job done
- Scalability Issues: It will be a bottleneck if a team need to do for all customers
- Data Loss: If some task is executed out of order you might lose data.
- Downtime: Depending on the mistake or error it could affect availability.
Dynomite Use Cases and Topology
I use dynomite as cache but also as a source of truth. When you think as a cache only remediation is great but less critical since something went wrong or takes more time it's fine since is a cache and you are not losing any data. Worst case you are adding more latency to the application, depending on your volume that might or might not be acceptable at all.
When we are talking about Source of Truth use case is a different deal since we can't afford losing Data. Thanks to Netflix awesome engineers there is a killer feature in Dynomite Manager called Cold Bootstrapping. This feature is very important for 2 reasons, first because allow dynomite / redis nodes to a recovery process when a node dies or got terminated - so the node can peer up with other nodes and get nearby data and they join the cluster without losing data. The same feature allows to perform remediation without downtime if we are careful and execute steps in very narrow and specific order.
Typical a dynomite cluster has 3 nodes as minimum topology. There is 1 node per AZ so this helps us to achieve high availability. You can have bitter clusters but will be always multiple of 3, like 3,6,9,12,15,18,21 nodes and so on and on.
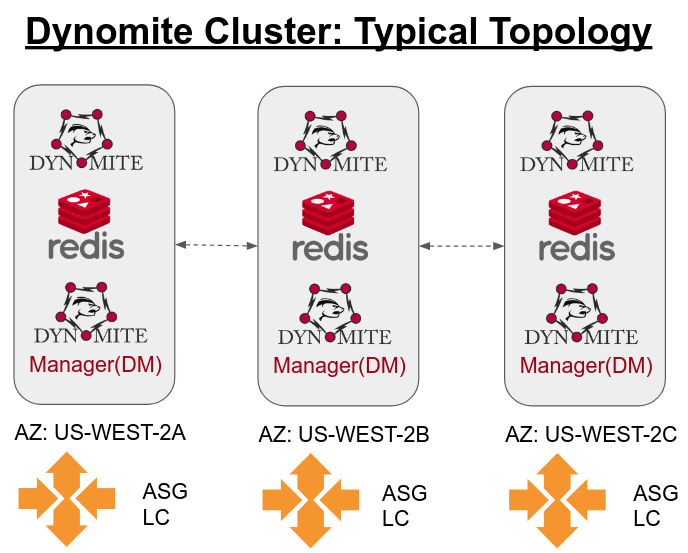
In order to do a proper remediation, there are 3 main requirements we need to meet. First of all, we need to be fully automated them we also need to make sure we don't lose data and we don't create downtime for our consumers.
It's possible to avoid downtime because dynomite has dyno. Dyno is cluster and topology aware so it knows other nodes in other AZ so when a node is down it will failover to the other node and that's the reason why we can do the process without downtime. Dyno has some other interesting concept called LOCAL_RACK or LOCAL_AZ which allow you to have a preferable AZ to connect this allow you reduce latency and get nearby AZ.
In order to the remediation process work, dyno needs to be fully and properly configured and you need to have a proper cluster, in sense of topology. Othwerise you might not meet the requirement of no downtime. Automation can be archived with AWS SDK which is available to most of the popular languages. The remediation solution I built was coded with Java 8. Overall JVM ecosystem is really great for troubleshooting, remote debug and profiling so this was one of the reasons behind the rationale plus my company I work for is a Java shop so :D.

Dynomite Remediation Process Flow
Right now we can talk about the remediation process. This process had to be coded very carefully in sense of timeouts, retry and make sure the steps and execute at the right moment. Forst instance first thinks the process does is to discover the cluster based on the ASG Name. Here I use the AWS API in order to get all dynomite nodes given cluster name which is unique.
Once I have the IPs that I can check is the nodes are healthy and if is a good time to start a remediation process. The first question makes sense and is easy to grasp because we want to know if the node is UP and RUNNING howe the er second question makes more sense if we think about Dynomite-Manager(DM). DM might be running some Backup yo S3 or might be performing some cold bootstrapping with redis since a node might just die or could be restoring data from S3 no matter the case this is pretty good examples of things that could be happing and you supposed to wait for all these events finish before remediation starts or proceed. That's why calling the Dynomite-Manager Health Checker is so important and thanks to Netflix great engineer it exposes all information we need to know in order to perform this process in a safe and reliable manner.
In order to apply patches or increase instance family, we need to create new Launch configurations pointing to new AMI IDS and we need to update Auto-Scaling Groups to point to these new LCs. Them we can kill node by node in order to remediate the cluster. After all, nodes are remediated we can delete the 3 old LCs(1 per AZ) and we are done.
When we kill a node there are operations that will happen and we will need to wait for this operations to be finished in order to move to the next node. First we need wait AWS ASG bootup a new node, then we need wait dynomite and DM bootup and DM will realize it needs to run some cold bootstrap in order to copy data from other Redis nodes, once that process is done DM health Checker will let us know and then we can proceed to next node.
Here is the visual picture of the whole remediation process flow.

Remediation process is great and saves lots of times. The whole remediation process is a bit slow since we need wait AWS to kill and boot up new instances. On average a 3 node cluster takes about 15 minutes to be remediated. This time may vary depending on how much data do you have in Redis.
Other Dynomite related Posts
- Lessons Learned using AWS Lambda as Remediation System
- Getting Started with Dyno Queues
- Running Dynomite on AWS with Docker in multi-host network Overlay
- Dynomite Eureka Registry with Prana
- Dynomite and RocksDB running on Docker
- Running Netflix Dynomite and Dynomite-Manager at AWS Cloud
Diego Pacheco


